---
title: "Mejores Universidades del Mundo"
description: |
Analizaremos los datos del ranking de las mejores Universidades del mundo en 2023
author:
- name: Jorge Moreno
affiliation: Universitat de València
affiliation-url: https://www.uv.es
date: 2026-01-05 #--
categories: [trabajo BigData, Universidades, Ranking] #--
favicon: "./imagenes/uv.png"
title-block-banner: true #- {true, false, "green","#AA0000"}
title-block-banner-color: "white" #-"#FFFFFF"
toc-depth: 3
smooth-scroll: true
format:
html:
#backgroundcolor: "#F4FAF2"
#embed-resources: true
link-external-newwindow: true
#css: assets/my_css_file.css #- CUIDADO!!!!
code-tools: true
code-link: true
include-in-header:
- text: |
<link rel = "shortcut icon" href = "imagenes/uv.jpg" />
---
## INTRODUCCIÓN
Ya que todos nosotros estamos a punto de acabar la etapa universitaria, no se me ha ocurrido mejor idea que hacer un análisis de las mejores universidades del mundo. Para ello he obtenido en Kaggle un ranking de las mejores universidades del mundo del año 2023, los datos se pueden ver [aquí](https://www.kaggle.com/api/v1/datasets/download/alitaqi000/world-university-rankings-2023)
Cargamos y arreglamos los datos en la memoria de de R/RStudio de esta forma:
```{r}
#instalamos los paquetes necesarios
library("tidyverse")
library("dplyr")
library("ggplot2")
library("sf")
#install.packages("ggwordcloud")
library("ggwordcloud")
#install.packages("treemapify")
library("treemapify")
#install.packages("ggrepel")
library("ggrepel")
# crear una carpeta llamada datos
fs::dir_create("datos")
# los datos son importados de la pagina web de Kaggle de un dataset sobre coches
my_url <- "https://www.kaggle.com/api/v1/datasets/download/alitaqi000/world-university-rankings-2023"
# definir la ruta
my_destino <- "./datos/unis.csv"
# descargamos el archivo, al ser de kaggle se descarga ya como csv
curl::curl_download(my_url, my_destino)
# importar los datos a un df
df <- readr::read_csv("./datos/unis.csv")
# vemos la estructura del DF
str(df)
#Como vemos en la estructura, hay variables numericas que se estan concebidas como character por lo que las cambiamos a numeric
#Uso drop_na para simplificar la muestra a 200 observaciones ya que habian muchas universidades en un rango de puestos del ranking
df_1 <- df %>%
mutate(across(c(1, 8:13), as.numeric)) %>%
drop_na("University Rank")
#tenemos una columna que nos da una ratio .:. sobre el porcentaje de mujeres y hombres. Para pasarlo a numeric,
#tenemos que quitar esa estructura con la funcion separate y crear dos columnas con ambos valores de los porcentajes
df_sin_porcent_1 <- df_1 %>%
separate("Female:Male Ratio", into = c("Porcentaje_Muj", "Porcentaje_Hombr"), sep = " : ") %>%
mutate(across(c(Porcentaje_Muj, Porcentaje_Hombr), as.numeric))
#para finalizar de arreglar nuestras columnas, tenemos que suprimir el simbolo de porcentaje (%) de la columna international student
#utilizaremos la funcionn gsub para quitarlo y convertimos la columna a numerico
df_sin_porcent_2 <- df_sin_porcent_1 %>%
rename("prcnt_est_int" = "International Student") %>%
mutate(prcnt_est_int = as.numeric(gsub("%", "", prcnt_est_int)))
#renombramos lo que no nos interesa para el analisis
str(df_sin_porcent_2)
df_FINAL <- df_sin_porcent_2 %>%
rename (PUNTUACION_DE_LA_UNIVERSIDAD = "OverAll Score")%>%
rename (NOMBRE_DE_LA_UNI = "Name of University")%>%
rename (PAIS = "Location")%>%
rename (NUMERO_DE_ESTUDIANTES = "No of student")%>%
rename (PORCENTAJE_DE_INTERNACIONALES = prcnt_est_int) %>%
rename (PORCENTAJE_MUJERES = Porcentaje_Muj) %>%
rename (PORCENTAJE_HOMBRES = Porcentaje_Hombr) %>%
select (-"No of student per staff",
-"Teaching Score",
-"Research Score",
-"Citations Score",
-"Industry Income Score",
-"International Outlook Score",
-"University Rank")
#borramos lo que no nos interesa del Global
rm(list = ls()[ls() != "df_FINAL"])
```
El dataset final contiene 7 variables con 199 observaciones. Haremos el análisis sobre este conjunto de datos final.
------------------------------------------------------------------------
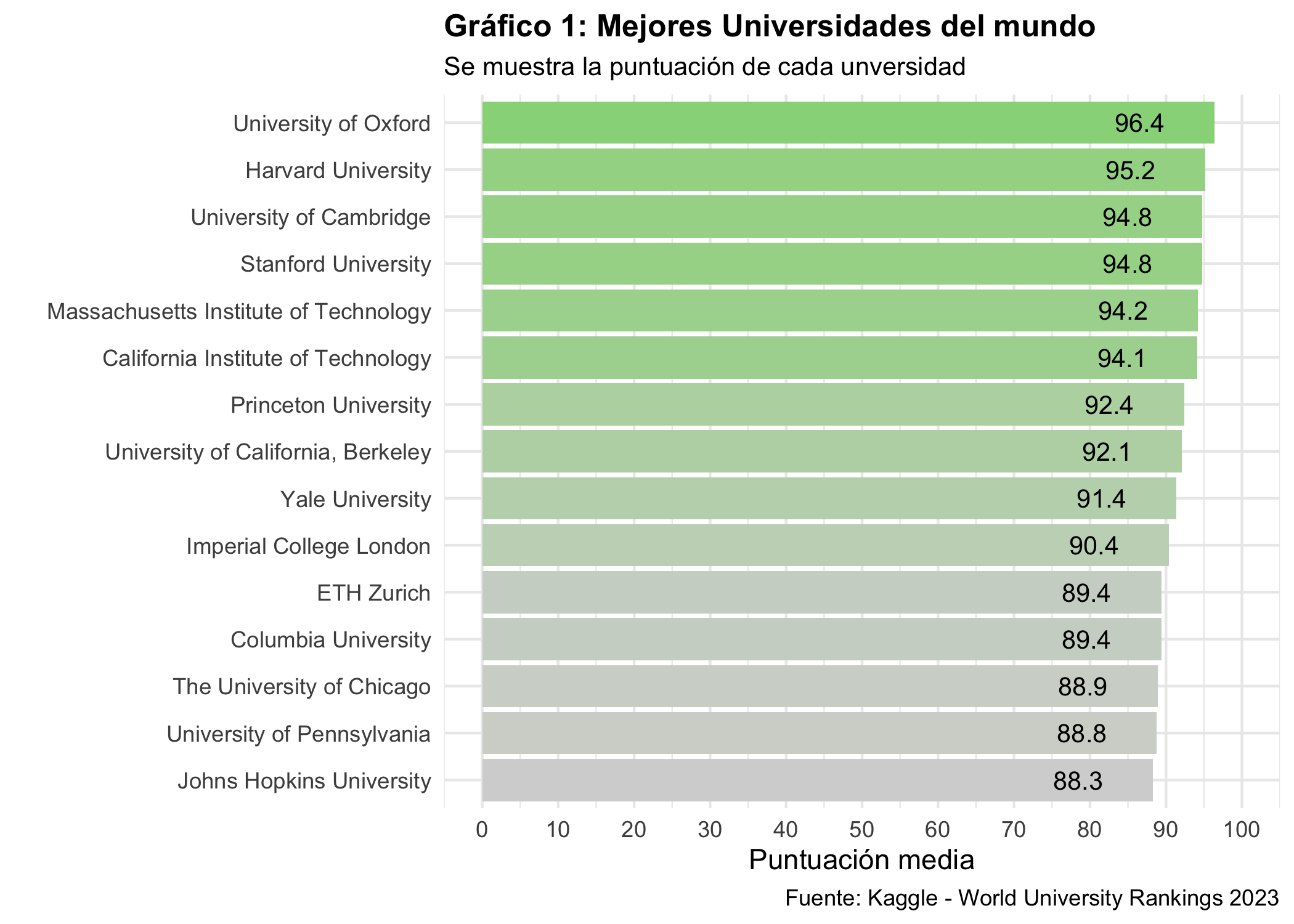
## Top 15 Univeridades del mundo
El gráfico presenta el Top 15 de las mejores universidades del mundo en 2023, liderado por la University of Oxford con una puntuación de 96.4. Se observa una competitividad extrema, ya que la diferencia entre el primer y el decimoquinto puesto es de apenas 7.6 puntos. Predominan los centros anglosajones, destacando también la presencia europea con el ETH Zurich.
```{r}
#| echo: true
df_analisis_1 <- df_FINAL %>%
arrange(PUNTUACION_DE_LA_UNIVERSIDAD) %>%
slice_max(PUNTUACION_DE_LA_UNIVERSIDAD, n = 15)
p1 <- ggplot(df_analisis_1, aes(x = PUNTUACION_DE_LA_UNIVERSIDAD, y = reorder(NOMBRE_DE_LA_UNI, PUNTUACION_DE_LA_UNIVERSIDAD), fill = PUNTUACION_DE_LA_UNIVERSIDAD)) +
geom_col() +
geom_text(aes(label = PUNTUACION_DE_LA_UNIVERSIDAD), hjust = 2, size = 3.5, color = "black") +
scale_fill_gradient(low = "#D5D5D5", high = "#98D688")+
labs(title = "Gráfico 1: Mejores Universidades del mundo",
subtitle = "Se muestra la puntuación de cada unversidad",
caption = "Fuente: Kaggle - World University Rankings 2023",
x = "Puntuación media",
y = "") +
scale_x_continuous(limits = c(0, 100),
breaks = seq(0, 100, 10)) +
theme_minimal() +
theme(legend.position = "none",
plot.title = element_text(face = "bold", size = 12),
plot.subtitle = element_text(face = NULL ,size = 10))
p1
```

------------------------------------------------------------------------
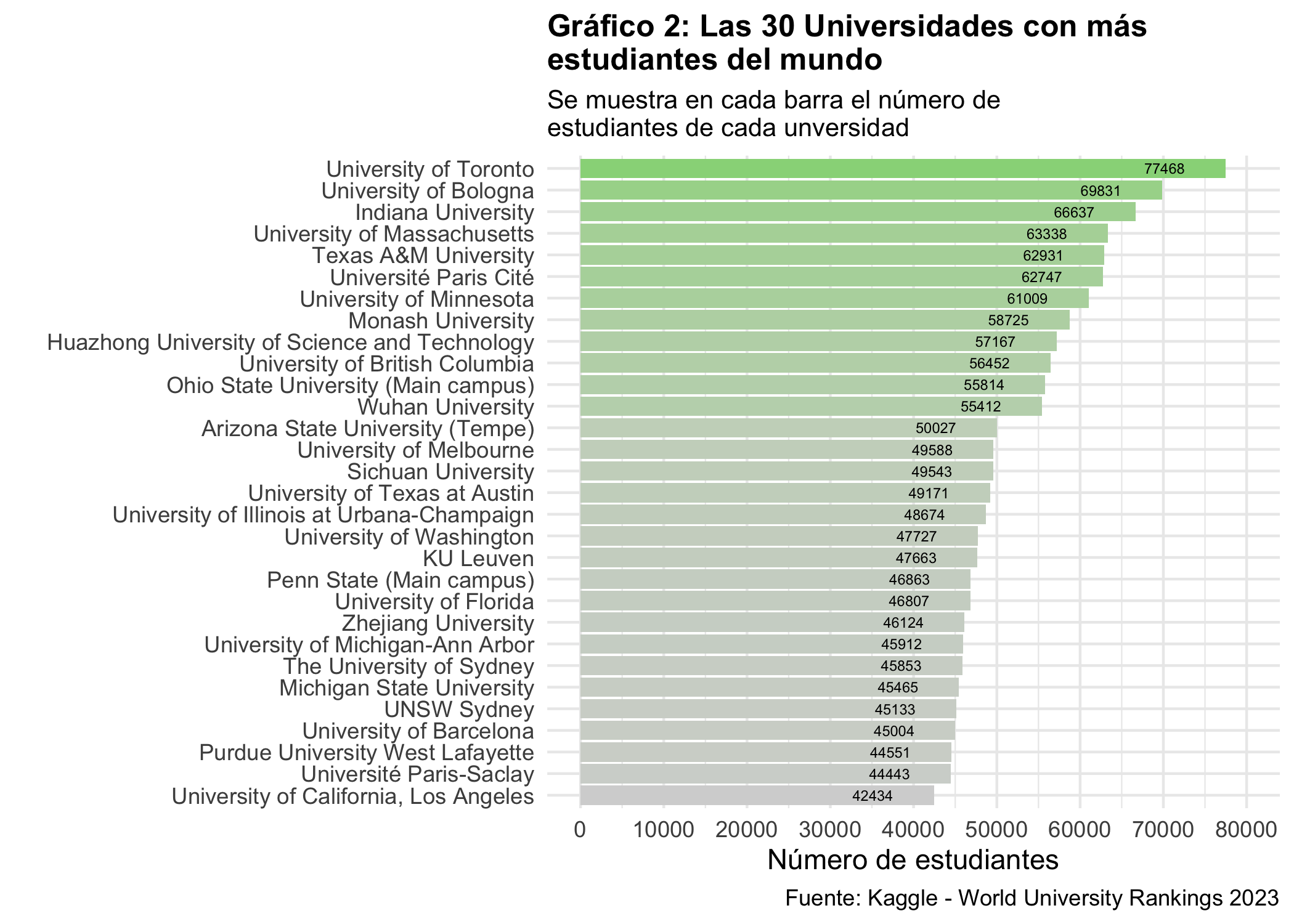
## Las 30 Universidades con más estudiantes del mundo
Para continuar, vamos a hacer un análisis de las 30 Universidades con más estudiantes del mundo mostrando el número de estudiantes de cada una. El gráfico revela que la University of Toronto lidera la lista con una cifra impresionante de 77.468 alumnos, seguida por la University of Bologna con 69.831. Se observa una gran diversidad geográfica en las instituciones de alta densidad, incluyendo centros de EE. UU., Europa y China, como la Wuhan University.
```{r}
#| eval: true
df_analisis_2 <- df_FINAL %>%
arrange(NUMERO_DE_ESTUDIANTES) %>%
slice_max(NUMERO_DE_ESTUDIANTES, n = 30)
p2 <- ggplot(df_analisis_2, aes(x = NUMERO_DE_ESTUDIANTES, y = reorder(NOMBRE_DE_LA_UNI, NUMERO_DE_ESTUDIANTES), fill = NUMERO_DE_ESTUDIANTES)) +
geom_col() +
geom_text(aes(label = NUMERO_DE_ESTUDIANTES), hjust = 2, size = 2, color = "black") +
scale_fill_gradient(low = "#D5D5D5", high = "#98D688")+
labs(title = "Gráfico 2: Las 30 Universidades con más\nestudiantes del mundo",
subtitle = "Se muestra en cada barra el número de\nestudiantes de cada unversidad",
caption = "Fuente: Kaggle - World University Rankings 2023",
x = "Número de estudiantes",
y = "") +
scale_x_continuous(limits = c(0, 80000),
breaks = seq(0, 80000, 10000)) +
theme_minimal() +
theme(legend.position = "none",
plot.title = element_text(face = "bold", size = 12),
plot.subtitle = element_text(face = NULL ,size = 10,))
p2
```

------------------------------------------------------------------------
## Los países con mayor número de Universidades en el Ranking
En este apartado, identificamos los países con mayor presencia de universidades en el ranking mundial mediante una nube de palabras (wordcloud). El gráfico destaca visualmente el dominio de Estados Unidos, Reino Unido y Alemania, cuyos nombres aparecen con mayor tamaño debido a su alto volumen de instituciones clasificadas. También se observa una representación significativa de naciones como Australia, China, Países Bajos y España, lo que refleja un ecosistema educativo global diverso. Esta visualización permite comprender rápidamente qué regiones concentran el mayor prestigio académico internacional.
```{r}
df_analisis_3 <- df_FINAL %>%
filter(!is.na(PAIS)) %>%
group_by(PAIS) %>%
summarise(Numero_de_unis = n()) %>%
arrange(desc(Numero_de_unis))
set.seed(1)
p3 <- ggplot(df_analisis_3, aes(label = PAIS, size = Numero_de_unis, color = Numero_de_unis)) +
geom_text_wordcloud() +
scale_size_area(max_size = 25) +
scale_color_gradient(low = "#727D84", high = "#49525E")+
labs(title = "Gráfico 3: Los países con mayor número de\nUniversidades en el Ranking",
caption = "Fuente: Kaggle - World University Rankings 2023") +
theme_minimal() +
theme(legend.position = "none",
plot.title = element_text(face = "bold", size = 16, hjust = 0.5))
p3
```
## Universidades con mayor número de estudiantes internacionales
En este nivel de análisis, exploramos las 40 universidades con mayor número de estudiantes internacionales, representadas en un gráfico de rectángulos o treemap. Instituciones como la University of Toronto, The University of Sydney y UCL destacan por sus grandes áreas, reflejando su enorme capacidad de atracción de talento global.
```{r}
df_analisis_4 <- df_FINAL %>%
filter(!is.na(PORCENTAJE_DE_INTERNACIONALES)) %>%
mutate(NUM_INTERACIONALES = PORCENTAJE_DE_INTERNACIONALES*NUMERO_DE_ESTUDIANTES/100,.after = PORCENTAJE_DE_INTERNACIONALES)%>%
select(NUM_INTERACIONALES,NOMBRE_DE_LA_UNI)%>%
slice_max(order_by = NUM_INTERACIONALES, n = 40)
p4 <- ggplot(df_analisis_4, aes(area = NUM_INTERACIONALES, fill = NUM_INTERACIONALES, label = stringr::str_wrap(NOMBRE_DE_LA_UNI, width = 15)))+
geom_treemap(colour = "black", size = 0.5) +
geom_treemap_text(colour = "black",
place = "centre",
size = 10) +
scale_fill_gradient(low = "#D5D5D5", high = "#98D688") +
labs(title = "Gráfico 4: Las 40 Universidades con mayor\nnúmero de estudiantes internacionales",
caption = "Fuente: Kaggle - World University Rankings 2023") +
theme_minimal() +
theme(legend.position = "none",
plot.title = element_text(face = "bold", size = 12, hjust = 0.5))
p4
```
Se observa una fuerte presencia de universidades australianas y británicas, que tradicionalmente lideran en diversidad cultural. Esta visualización permite identificar rápidamente qué centros actúan como verdaderos nodos de intercambio académico mundial.
------------------------------------------------------------------------
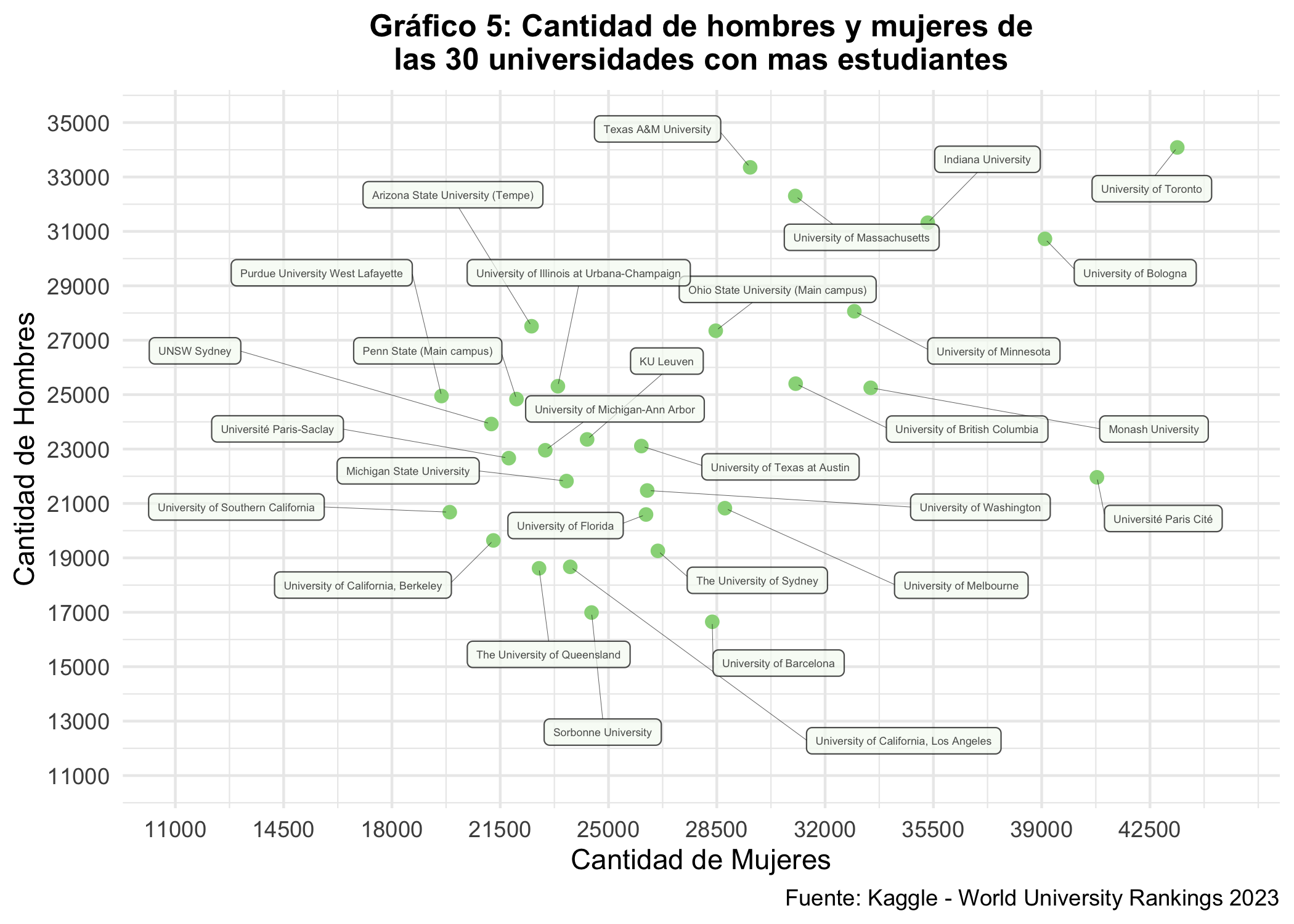
## Cantidad de hombres y mujeres de las universidades con mayor número estudiantes
Para concluir, examinamos la cantidad de hombres y mujeres en las 30 universidades con mayor número de estudiantes mediante un gráfico de dispersión. Se observa una distribución variada, donde instituciones como la University of Toronto y la University of Bologna muestran un volumen elevado en ambos géneros, superando los 30,000 estudiantes por categoría.
```{r}
df_analisis_5 <- df_FINAL %>%
mutate(NUMERO_HOMBRES = (PORCENTAJE_HOMBRES * NUMERO_DE_ESTUDIANTES)/100,.before = PORCENTAJE_HOMBRES) %>%
mutate(NUMERO_MUJERES = NUMERO_DE_ESTUDIANTES-NUMERO_HOMBRES, .before = PORCENTAJE_MUJERES)%>%
filter(!is.na(NUMERO_MUJERES),!is.na(NUMERO_HOMBRES))%>%
select(NOMBRE_DE_LA_UNI,NUMERO_MUJERES,NUMERO_HOMBRES,NUMERO_DE_ESTUDIANTES)%>%
slice_max(order_by = NUMERO_DE_ESTUDIANTES, n = 30)
p5 <- ggplot(df_analisis_5, aes(x = NUMERO_MUJERES, y = NUMERO_HOMBRES, label = NOMBRE_DE_LA_UNI)) +
geom_point(color = "#98D688", size = 2) +
geom_label_repel(size = 1.5,
max.overlaps = Inf,
box.padding = 0.7,
segment.size = 0.1,
fill = "#F4FAF2",
alpha = 0.7) +
scale_x_continuous(limits = c(11000, 45000),
breaks = seq(11000, 45000, 3500)) +
scale_y_continuous(limits = c(11000, 35000),
breaks = seq(11000, 35000, 2000)) +
labs(title = "Gráfico 5: Cantidad de hombres y mujeres de\nlas 30 universidades con mas estudiantes",
caption = "Fuente: Kaggle - World University Rankings 2023",
x = "Cantidad de Mujeres",
y = "Cantidad de Hombres") +
theme_minimal() +
theme(legend.position = "none",
plot.title = element_text(face = "bold", size = 12, hjust = 0.5))
p5
```
El gráfico permite identificar correlaciones interesantes, como la posición de Texas A&M University, que destaca por una de las mayores poblaciones masculinas del grupo. Esta visualización es clave para entender el equilibrio demográfico y la escala de diversidad en los centros educativos más grandes del mundo.
<br>
Con esto acabo mi trabajo para BigData!!
Agradecimientos a mi novia <3
<br>
------------------------------------------------------------------------
<br>
### Información sobre la sesión
Abajo muestro mi entorno de trabajo y paquetes utilizados
```{r}
#| echo: false
sessioninfo::session_info() %>%
details::details(summary = 'current session info')
```